STA 141C Big-data and Statistical Computing
Discussion 8: Tree-based Models
TA: Tesi Xiao
Decision Tree
- Pros
- Non-linear classifier
- Nonparametric
- Better interpretability with splitting nodes
- Fast prediction
- Cons
- Overfitting
- Slow training
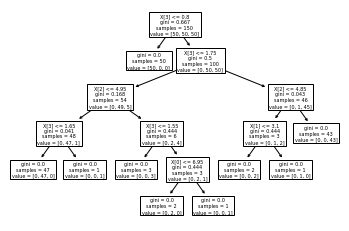
class sklearn.tree.DecisionTreeClassifier(*, criterion='gini', splitter='best', max_depth=None)
Criterion: Gini impurity vs. Information gain
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
tree.plot_tree(clf) # visualize the tree
Ensemble Model
(An aggregate of weak learners)
Multiple diverse models are created by using many different modeling algorithms or using different training data sets to predict one outcome. The ensemble model aggregates the prediction of each base model and results in once final prediction for the unseen data.
Bagging (Bootstrap aggregating)
In the ensemble, each model is created independently and votes with equal weight. Bagging trains each model in the ensemble using a randomly drawn subset of the training set
Example: Random forest (multiple decision trees)
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion='gini', max_depth=None)Boosting
Boosting involves incrementally (sequentially) building an ensemble by training each new model instance to emphasize the training instances that previous models mis-classified.
The new learner learns from the previous weak learners.
Example: Gradient Boosted Decision Trees (GBDT)